Macrobius
Megaphoron
Certain topics are rather timely, and no other topic fits the times than the topic of “The Dead Internet Theory”. First, as usual, a bit of history is necessary since this is a very niche part of net history. Even if at a superficial level, understanding Imageboard's self-contained culture, and its impact on culture itself is necessary. There a significant reasons why each and every single Large Language Model is trained on a corpus of scrapped data from 4chan. Terabyte worth of data.
From a descriptive perspective, Imageboards such as 4chan have been at the forefront of culture for the most part since their inception. The influence of specific boards (imagine a smaller section of the website centered around specific themes) has always been influential and disproportionate to its size, a true lesson is cascade effects in complex networks. How a small, secluded node of a system “affects” the rest. No wonder the UN, think tanks and even the DoD poured a few hundred million dollars (total) since 2015 into “researching” the boards.
It would take months to dissect each common, pop culture, or even niche “belief” that arose from image boards, but one in particular bears more weight today, than at the time—the Dead Internet Theory. I have the original post here, somewhere, but given how extensive my Imageboard dataset is, there is a chance close to 0 of me finding it. The original post was many years older than the following one, but they are close.
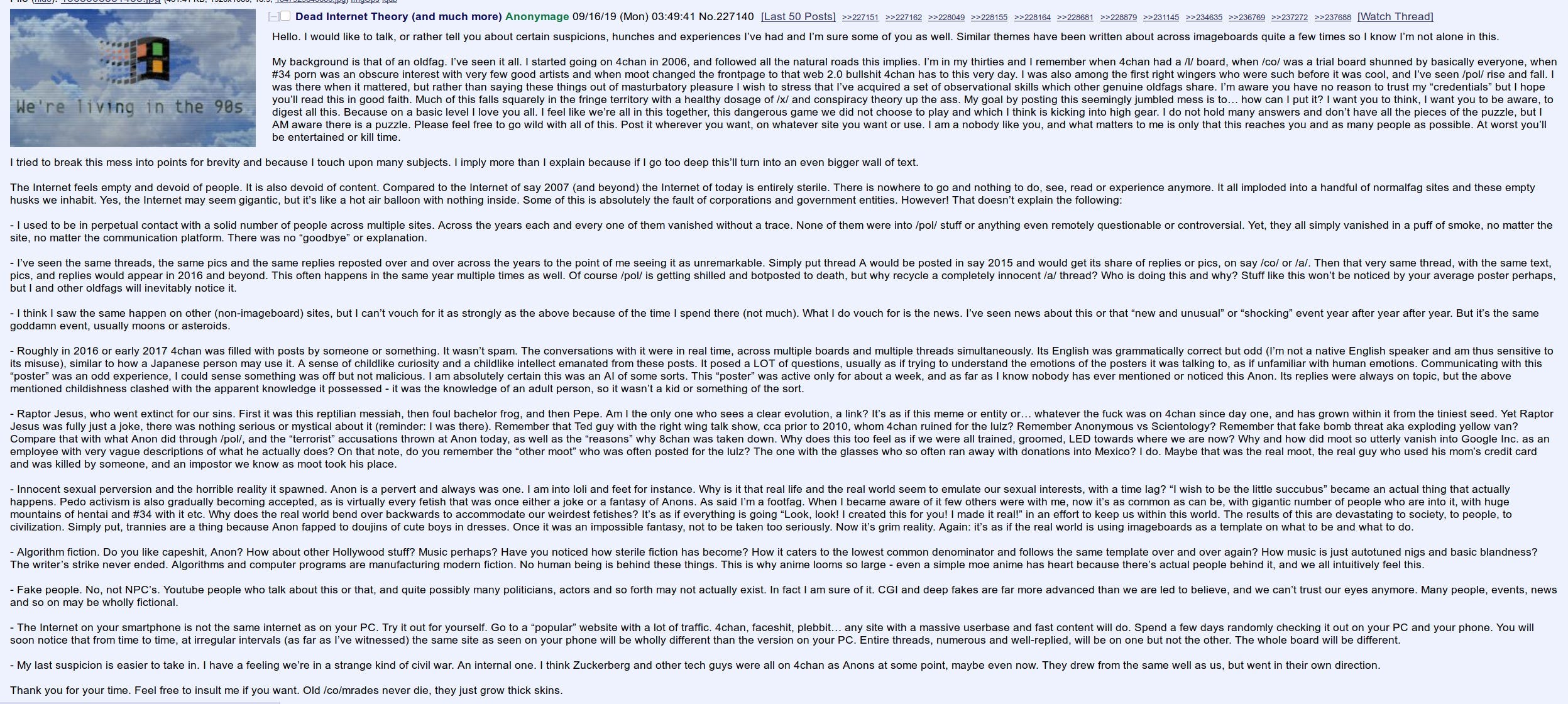
The text is loaded with Imageboard vernacular, and with the conspiracies that often are common among the crowd, but the brunt of the hypothesis is there. Ignore the conspiratorial part, focus on the prescient nature of the text. At the time of the original post, before 2014, I thought that was far-fetched, we were not even close to that level of capability, and we didn’t have the compute.
For quantifiability, a GPU today is as powerful as a 15 million dollar supercomputer of 2015, the disparity in computing power is hard to grasp sometimes. So what could explain the discrepancies in content quality, or what we call what is, or feels organic (made by humans), and what it is not (synthetic) ?
Early 90’s and early 2000’s internet felt alive because almost every dynamic involved in digital content was organic, most search algorithms and web crawlers were incredibly simplistic, you used a search term, it found results close to what you asked, and anyone with a few bucks could build a niche website for their hobby, beliefs, or whatever interested them. It felt organic because the business model was significantly different.
You had to pay someone for access to the internet, therefore the business model relied more on paying AOL or similar services rather than an advertising model, this changed in the early 2000s when ADSL (cable internet) became a common, industrial-scale service. A streamlined and much faster internet. Now it was possible to gather data at a much larger scale, much faster, analyze the data, and “serve” better ads, setting the path for data tracking and its profitability.

As algorithms grew in complexity and capability (algorithms in a basic sense are a set of instructions that a computer/program will follow), enabling quite proficient and detailed behavioral analysis, enabled the opportunity to commoditize users in multiple ways. Serving “better ads”, and making attention a commodity.
At its core, this was truly the birth of the “Attention Economy” first proposed by Herbert Simon decades ago. A very recent paper by Karthik Srinivasan proposes that attention is a form of currency, and its other proposition based on a large dataset (2 billion Reddit posts) is also poignant towards old and modern internet, such as low-quality content is necessary.
Effectively creating Attention Hacking as a business model, where you research, develop, and deploy complex algorithms, bordering black box design (a black box algo is when you don’t know exactly what is going on inside, but you get your desired outputs, LLMs are a perfect example of this) to “hack” your users at a psychological level to they get hooked up on that dopamine rollercoaster. TikTok is the perfect example of attention hacking done with scientific precision.
These deep changes in business model and the internet architecture itself drove some of the changes pointed out in the 4chan post, until very recently most of the content online was mostly organic, the quality level is arguable, but mostly done by humans. Synthetic content was mostly aimed as a very expensive, disruptive tool towards the goal of the organization applying rudimentary tools (bots).
An advertising-centric business model is great for both the main business, for organizations, for advertisers, and for everyone except the consumer, because it leverages attention and gives a substantial level of influence among the target audience.
Non-human (bots) traffic on the internet already accounts for almost half of the overall traffic, and 30% of these are considered “bad bots”. Bots are tools for scrapping data, but also mining information, boosting engagement online and other usages, and while they can mimic human behavior to do these tasks, they are considered basic tools. Up until early this year, you didn’t engage with bots for the most part, and their spam/scam behavior was pretty easy to differentiate. This has changed and probably will be forever changed as of early 2023.
At a very, very large scale (millions) bots can somewhat “nudge” society’s behavior into a desired direction, but bots suck at mimicking human language, therefore human thought, a degree of rational and logical thinking, and bots follow a somewhat precise list of tasks. That is out of the window. With the advent of Large Language Models (LLMs), and its arms race better models, we entered a new era of the internet.

LLMs enable the creation and usage of more refined (State of the Art - SOTA) “advanced bots” (they are not bots but it is easier to understand this way), referred to as “agents”, for the layperson a bot is a program that follows instructions and doesn’t think or learn by itself. Task it with X 100 times, you will get X 95, and the other 5 errors or something else. An agent is a quasi-autonomous “advanced bot”, it learns, adapts, and can improve itself in the path towards completing the task.
As with everything in life or technology, there are degrees to this, a fully autonomous agent is still quite a bit away from full realization, but remarkably competent agents were not only already developed, but deployed. Current-gen language models enable you to do the following “on the fly” with or without agents:
- Generation of writing, language-based content at an alarming scale
- Structured analysis of target niche or individual data
- Sentiment, psychological, and behavioral analysis of the structured data from the task above
- Deploying targeted content, “behavioral nudges” both at an individual level, but much more effectively at a large scale
- Generating both images and complete animated videos from a single picture (Gaussian splitting, just YouTube it, be amazed)
These are based on a single variable, an LLM or an agent, or what is the most likely usage, an LLM-based agent. But what we will experience very shortly are Agent Swarms.
A agent swarm, as the name implies is a large group of quasi/semi-autonomous digital entities that can be tasked with X, and do not need human supervision, or very minimal to achieve its primary goal. The swarms consist of numerous (a handful, a few dozen, hundreds, thousands) able to learn by themselves and help each other agents to learn and improve.
There are entire sections of the field of Machine Learning and artificial intelligence in which the sole purpose is to research, theorize, understand, and create functional tools to use swarm behavior. Swarm behavior is one of the most interesting fields in Complexity science since it is a primordial example of “self-organizing” chaos. As I said for years, chaos is just complexity you don’t understand =).
A hostile language model, especially one large enough, is already hard to deal with if it is hostile (meaning used for offensive purposes), but swarms will be incredibly harder to deal with because they are much smaller, faster, semi-autonomous, numerous and they do not behave like bots, they can almost perfectly (as of right now) imitate human behavior.
The most advanced models are capable of much, much more, but widespread access to very capable models, able to be further trained towards your specific goals is now widely available. The organic internet is now experiencing its “death”, accelerated by LLMs and the use of AI, because the business model is fueled by attention, a two-way commodity, both earning revenue and data, which is the new oil.
One of the most moronic recent changes in social media was rewarding “creators” and influencers with ad revenue, a level of stupidity which the consequences can be seen and read on Twitter. Charging a few per month to get you a tick mark, and as a reward financially compensating the account for engagement, set off an arms race of engagement farming. Because when you pay for that tick mark, and a few other variables, your content is significantly boosted.
This flood of useless, synthetic content, adding absurd levels of noise to social media has been occurring since early this year, but the scale that now occurs is staggering enough that even one of the co-founders of OpenAI has “low-key” been liking specific tweets (FYI he is one of the most honest, cool and down to Earth guys from the company).

Synthetic video content, meaning low-effort, viral videos have billions of views on TikTok. LLM text spreading specific information has also been flooding social media (per the screenshot). The internet isn’t dying because of synthetic content, or just the absurd volume machines can produce, but because of a few complex dynamics. The first, and the point of this article.
Narrative warfare, which is sold society-wide as “Fighting Disinformation”. I present you with one of the public companies, that recently earned a contract from the DoD. Accrete AI. There is a video presentation inside the link, and I insist you watch at least the first 10 to 15 minutes. It may open your eyes.

From the article announcing the DoD contract.
The US Special Operations Command (USSOCOM) has contracted New York-based Accrete AI to deploy software that detects “real time” disinformation threats on social media.
The company’s Argus anomaly detection AI software analyzes social media data, accurately capturing “emerging narratives” and generating intelligence reports for military forces to speedily neutralize disinformation threats.
“Synthetic media, including AI-generated viral narratives, deep fakes, and other harmful social media-based applications of AI, pose a serious threat to US national security and civil society,” Accrete founder and CEO Prashant Bhuyan said.
“Social media is widely recognized as an unregulated environment where adversaries routinely exploit reasoning vulnerabilities and manipulate behavior through the intentional spread of disinformation.
Accrete is just one of the leading, public companies. From a financial perspective, depending on how deep your pockets are, it doesn’t take much to execute everything I wrote here. It can take as little as 30.000 to 70.000 US dollars, and this amount lowers by the day, literally, I am only taking into account here someone wanting to own the hardware, you can easily rent hours of the most power GPUs in the market for a few bucks per hour to do it too.
For someone like me at this point in my life, 30.000 is an absurd amount of money, but for a company or research lab, 30.000 is a drop in the bucket. For a governmental agency or nation-state, it is a laughable amount. Bear in mind all the current architecture for anything AI-related is incredibly inefficient, it is power and compute-hungry, literal leviathans that want more, and more and more. A breakthrough in GPU or algorithmic/machine learning architecture and this trend accelerates, exponentially, once more.
This is not a “may”, or “will”, it is happening, right now, and has been going on for months. The only possible debatable point is scale, but we are at the exponential phase of this graph. Expensive, yes, but when your “bots” are financially rewarded for engagement and virality, it becomes a profitable business. The internet we know has changed, forever, its nature, architecture, content, and everything will now experience an accelerated rate of change.
Modern culture and modern society are influenced heavily by digital content, culture dictates politics, it dictates mass behavior, even at a certain level of intellect, and given what we discussed here, this will face significant change. We will see machines interacting with machines, to affect human behavior or their own behavior. The internet will become even more sanitized in many spaces, and completely unreliable on others.
Even Sam Altman has been saying for months, in public recorded interviews, how anxious he becomes knowing that LLMs and AI can easily persuade vast amounts of people, with ease. It is one of the main tenets of their new “Preparedness” initiative.

That illustrative was later added one….lmao
This path was inevitable, cyberpunk authors were very prescient in forecasting many of these events and changes, and so were some anonymous users on 4chan, old Twitter, and in random corners of the web. All of these last paragraphs are pre-swarm era, when agent swarm comes, with all shapes, sizes, and behaviors, well. You will see.
Both single, Large Language Model-based agents and Swarms will definitely affect culture, politics, economies, and society as a whole, target and general “cognitive operations” are already being executed by the first, with glimpses of a rudimentary version of the second all around for the eyes of those who want to see, see it.
These are all necessary data points for you to consider, both for your information consumption, and awareness, but also to understand the future pieces related to this topic, with relative special significance towards the next article, Language - The Genocidal Organ, and how memes, acting as genes of culture affect our reality. And nothing understands memes and language better than Large Language Models and Generative AI.
And just for my own amusement, a 2016 official document screenshot, from OpenAI.
[[ image at link ]]
- 30 -